Async Promise cache: How to avoid crashes when site traffic spikes 📈
Caching static content requests can significantly improve your server performance, and it's simple!

It's the dream of every single app builder or content creator — something you made goes viral! 🎉 Maybe a blog post, or a ProductHunt link, or even a celebrity Tweetbomb... whatever it is, something happens with a massive amount of eyeballs that suddenly want to visit YOUR thing.
Awesome, right?!
Well.. as the saying goes: "Be careful what you wish for!" Here is the traffic scenario your site will immediately experience, in a nutshell:
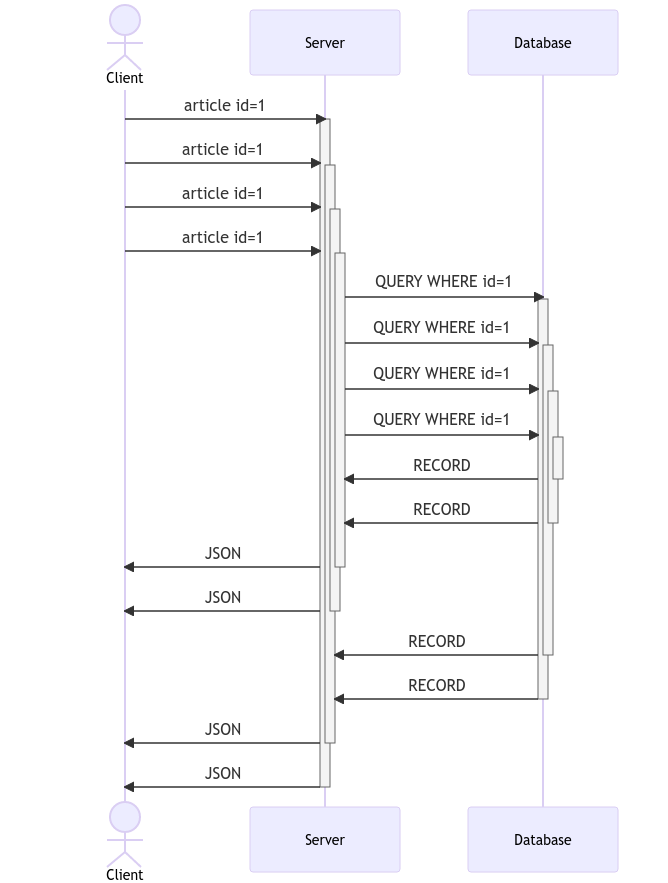
Your database might feel like this:

What's the big problem? Basically, it's a tsunami of traffic 🌊. Above, we're showing only 4 connections per second (not bad), but what if it's actaully 40, or 400, or 4000?? At some point, the API/database connection usage gets too intense, and will bottleneck the system by timing out or even crashing.
But before you go out and buy more database capacity and scale our web servers horizontally; FIRST let's see if there's something on the server we can do to minimize this problem. Your wallet will thank you! 💸 We can leverage the Promise cache pattern, which has a net effect like this:
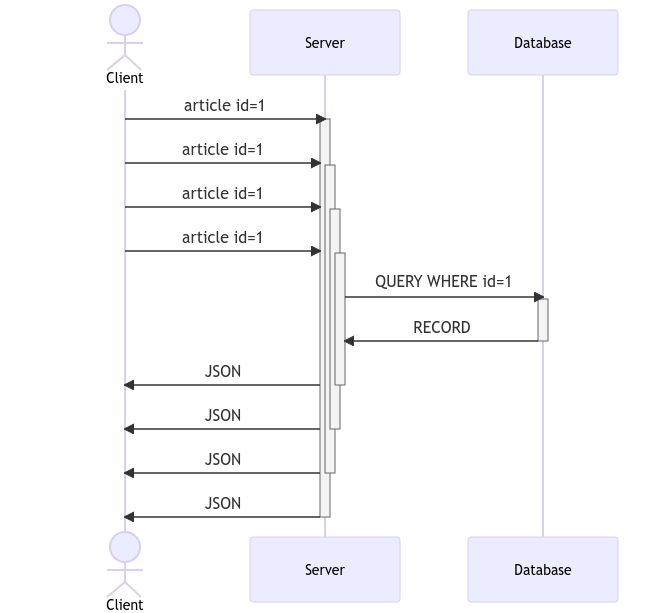
Ah! A fighting chance:

Isn't that so much nicer on the API/database connection side, with minimum connections required? What just happened? What secret sorcery 🪄 smoke-and-mirrors 🪞 trick is being played? How can we possibly accomplish this on our web server? I'm glad you asked 😁. Let's use a simple viral blog post as an example scenario, i.e. https://my-blog.com/super-viral-post that gets pummeled yet responds like a jiu-jitsu master.
We'll start by adding a simple caching layer between the business logic and the data fetching, using a Higher Order Function composition pattern. The cacher's API will work for our business logic layer something like this:
process-article-request-route.ts
import articleCacher from 'cacher';
const { articleId } = params;
const url = `https://my-blog.com/api/${articleId}`;
const thunk = async () => fetch(url); // Note: our thunk could do anything else, eg. call a DB, etc.
const articleData = await articleCacher(url, thunk); // Use a cache to call our thunk
// snip! Eg. logic to template response data, etc etc.
return response;
Like most other cache implementations, our cacher will use a simple JS object as state to store its Promises (we could also choose to use a Map or WeakMap):
cacher.ts
// key is the article URL, value is the Promised article content value
const cache: Record <string, Promise<any>> = {};
// snip!
Next, our public method will take its two params: a key, and a "thunk" callback cb which will provide the value:
cacher.ts
// key is the aricle URL, value is the Promised article content value
const cache: Record <string, Promise<any>> = {};
type CB = () => Promise<any>;
export default async function cacher(id: string, cb: CB) {
// snip!
}
We use the id as the key of our Promise, and check for its existence in our cache. If it doesn't exist, then we populate it with cb's Promise:
cacher.ts
const cache: Record <string, Promise<any>> = {};
type CB = () => Promise<any>;
export default async function cacher(id: string, cb: CB) {
if (!cache[id]) {
cache[id] = cb();
}
// snip!
}
Finally, we always return the cached Promise (not the awaited/resolved value!) back to the caller:
cacher.ts
const cache: Record <string, Promise<any>> = {};
type CB = () => Promise<any>;
export default async function cacher(id: string, cb: CB) {
if (!cache[id]) {
cache[id] = cb();
}
return cache[id];
}
As a bonus step 💯: we're going to help maintain a healthy cache by clearing out the Promise entry after it's been fetched. We'll do this inside a finally block (link). This invalidation feature mitigates our long-running cache from exploding in memory footprint; it also means that we are only caching once per "wave/batch" of API/database calls, to help avoid the cache from getting too stale:
cacher.ts
const cache: Record <string, Promise<any>> = {};
type CB = () => Promise<any>;
export default async function cacher(id: string, cb: CB) {
if (cache[id] === undefined) {
cache[id] = cb()
.finally(() => { delete cache[id] });
}
return cache[id];
}
Note: You may have already guessed, but if your article page is only made up of static content, you might even be able to move the caching layer higher up in your function call stack! (Unless you have logged-in users, in which case might mean a more dynamically/custom rendered article page.)
Finally, you might consider instead using a TTL strategy for cache invalidation; once per hour, or once per day? Or a LRU strategy; a max of four keys in the cache. This exercise is left up to the reader! 🤔
🌈 Editor's Note:
Please read PART 2, where you can learn how to implement these two strategies!
P.S. Yes, using a CDN can help manage a traffic spike, too. For starters, I highly recommend CloudFlare as your site's DNS provider.
And that's all there is to it! Understanding these advanced techniques and concepts will give you additional tools for many other async situations, so they're 💯 worth mastering!
You can follow me on Twitter and YouTube. Let’s continue interesting conversations about Sr JS development together!




